阅读本文大概需要15分钟。这是快速入门爬虫的第一篇,本系列文章将带领你从0基础开始,一步一步,从采集一个简单的网页,到复杂的列表,多页数据,Ajax页面,瀑布流等等,直到应对常见封IP,验证码等防采集措施,包括采集淘宝,京东,微信,大众点评等热门网站。由浅入深,循序渐进的深入网页数据采集领域,相信认真学完本系列,你也会成为采集大神,有能力把互联网变成自己的数据库(这一段提到了Ajax等专业数据,你可能不懂,但有个好消息:到目前为止你不需要了解这些技术概念)。
学习本篇内容,你需要先掌握以下知识:
- 会上网,知道什么是网页,什么是网址,什么是浏览器。
- 会使用windows XP,windows 7,windows 8.1,windows 10等操作系统,会使用Excel。
- 没有了,如果1、2点有不懂的,我墙裂建议你百度一下。
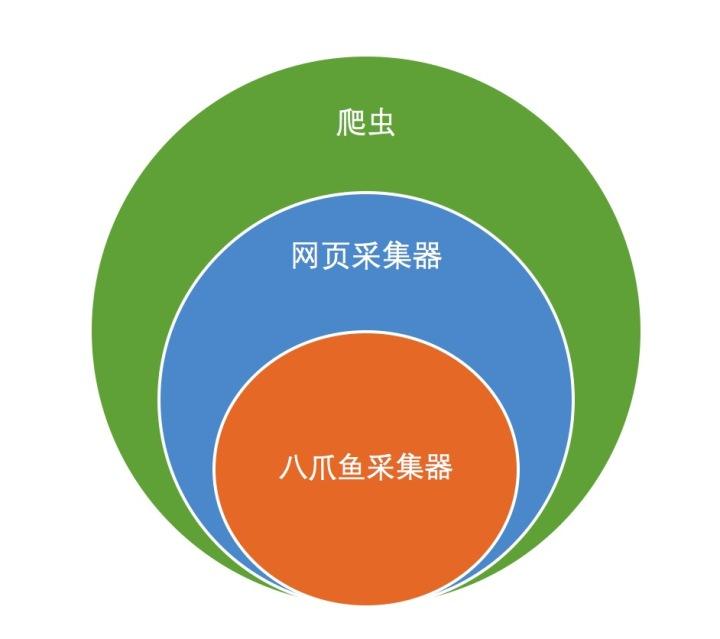
- 什么是爬虫,什么是网页采集器,八爪鱼采集器是什么。
- 使用八爪鱼采集器采集一个新闻网页,获取一条新闻数据。
好了,能读到这里我相信上面的要求对你而言太容易达到了。因为有了百度、知乎这些知识平台,我相信查询一个名词很容易,除非你是伸手党。但是往往这些名词的解释过于专业,同时又提到更多专业术语,容易让人困惑,所以我这里给出的解释不一定那么专业严谨,但是却通俗易懂。
- 什么是爬虫:我们讲的不是真正的动物或者小虫子,而是一些自动化的程序或者软件,会自动浏览网页,并从网页上获取内容。百度就是一个典型的爬虫,百度从各个网站上自动浏览网页,然后把网页内容存起来,给我们提供了一个搜索的工具,我们输入关键词,百度就会搜索爬虫保存的网页内容,罗列相关网站当做搜索结果。
- 什么是网页采集器:我这里讲的网页采集器专门指会根据用户的指令或者设置,从指定的网页上获取用户指定内容的工具软件。严格来讲,我这里说的网页采集器也是爬虫的一种。
- 八爪鱼采集器:八爪鱼采集器就是一种网页采集器,用户可以设置从哪个网站爬取数据,爬取那些数据,爬取什么范围的数据,什么时候去爬取数据,爬取的数据如何保存等等。

接下来,让我们从一个最简答的任务开始,采集一篇新闻(一个网页),上手操作一下如何采集数据。 开始采集之前,你需要下载并安装八爪鱼采集器,八爪鱼采集器目前仅支持windows操作系统,如果你正在使用Mac电脑或者Linux操作系统,请更换一台电脑,或者在Mac、Linux上安装windows虚拟机,然后在windows虚拟机上安装八爪鱼采集器。你可以百度如何安装虚拟机,我稍后会专门写一篇文章讲解如何通过虚拟机来安装八爪鱼采集器。 1. 下载八爪鱼采集器:免费下载 – 八爪鱼采集器,网址:http://www.bazhuayu.com/download。注意:截止本文发稿时,八爪鱼采集器最新版本为7.1.6。八爪鱼官网同时提供了6.4.5版本和7.1.6版本的下载链接(注意下载按钮下面的小字链接)。
你也可以直接点击这个链接下载八爪鱼采集器最新版本:http://www.bazhuayu.com/Download/DownloadHandler?version=new&from=minor,我建议大家总是下载最新版本,八爪鱼大概每个月升级1-2次,因此后续可能有更新的版本,但是就本教程的内容而言,新版本的主要操作学习过程不会有大变化,但是新版本通常性能更好,稳定性更高。 注:如果安装过程碰到任何问题,请点击链接:八爪鱼论坛安装问题板块,查看常见问题及解决方法。如果您使用的是window xp操作系统,则可能需要安装一个windows系统组件:.NET Framework 3.5 SP1,简称.NET 3.5。八爪鱼采集器需要.NET3.5 SP1支持,Win 7/8/10已经内置支持,无需下载,但XP系统需要安装,软件会在安装时自动检测是否安装了.NET 3.5 SP1,如果没有安装则会自动从微软官方在线安装,国内在线安装速度很慢,建议先从以下链接下载安装.NET 3.5 SP1,然后再安装八爪鱼采集器。点击这里下载.NET3.5 SP1 离线安装包。2. 安装八爪鱼采集器:下载后是一个zip文件,解压缩,然后运行里面的 OctopusSetup7.1.6.11022.exe,这个安装文件。
不同版本可能名字具体不一样,但是下载的zip压缩文件中只有这一个exe文件,其他还有几个txt文件。安装过程很简单,20秒左右就安装完成了。安装完成后,点击安装完成界面的“立即体验”按钮,或者在桌面上双击“八爪鱼采集器”快捷方式,就可以启动八爪鱼采集器了。 3. 注册并登陆八爪鱼账号,八爪鱼客户端需要登陆才能使用,不过好消息是,使用一个手机号或者邮箱就可以免费注册。点击八爪鱼采集器客户端登录界面的“免费注册”链接:
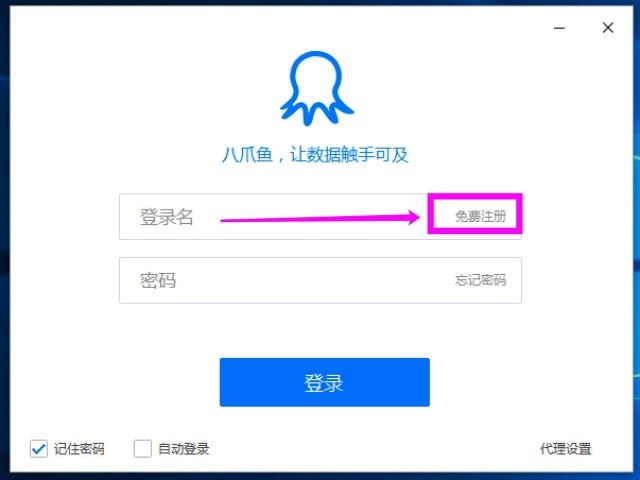
或者你也可以直接到八爪鱼网站免费注册:注册八爪鱼 – 八爪鱼采集器,网址:http://www.bazhuayu.com/signup。使用注册的用户名和密码登录后,将默认打开八爪鱼采集器主界面:
1. 复制上面的网址,打开网页浏览器(IE,火狐,Chrome、safari等等),把网址粘贴到浏览器地址栏,打开这个网页。 2. 选中标题部分的文字,按鼠标右键或者Ctrl+C复制选中文字,新建一个Excel文件,打开,并且粘贴到第一个单元格,然后复制时间,粘贴到第二个单元格,然后复制正文,粘贴到第三个单元格。为了让别人知道这些数据列都是什么,你可能会给三列分别加上列名,如:标题,时间,正文。结果如图:

因为操作步骤较多,下面是一个1分钟的视频给大家详细看看操作过程。可以看到系统在新打开的页面上自动打开了网页,采集了三个数据列,名字就是我们之前设定的,完成后提示我们导出数据,我们选择导出到Excel 2007,保存到桌面,然后打开Excel,是不是跟我们上面手动复制的数据效果一模一样?(其实本身很简单的,因为是0基础入门,我就讲的特别详细,如果觉得啰嗦欢迎大家给我留言提修改意见,请暂时忽略本教程没有提到的内容,我们在后续的文章中会讲解)https://www.zhihu.com/video/911035850404560896 这个很容易理解吧,这也正是八爪鱼设计最为精妙的地方,不像其他采集工具,需要你去理解计算机内部如何工作,八爪鱼就像是一个机器人,我们要做的就是训练这个机器人,教他按照我们设定的步骤一步一步像人一样去采集数据,唯一的区别就是,八爪鱼是程序,他会不知疲倦的,全自动的工作。
小结: 首先恭喜你!你已经入门了,从完全不懂爬虫,到自己成功采集了一篇新闻数据,保存到了Excel中,这是个非常大的进步!除非你不看教程已经可以做到这个结果,否则不要因为这个教程太简单而不去实践操作,我们后面会学习更多,但是都离不开这里学习的基础,而且采集其他任何网站,采集更多数据,其实都是一样的过程,只是采集的设置过程可能更复杂而已。如果你想跑,请先学会走。
如果你有任何问题和想法想和我交流,请在下面评论区留言。你也可以关注我的知乎与我互动:点击前往关注“刘宝强的知乎”。同时欢迎你关注我的知乎专栏获取新文章通知:点击前往关注“小白的数据梦工厂”
声明:本文由网站用户香香发表,超梦电商平台仅提供信息存储服务,版权归原作者所有。若发现本站文章存在版权问题,如发现文章、图片等侵权行为,请联系我们删除。